ClickHouse was specifically designed to work in clusters located in different data centers. The DBMS can be scaled linearly(Horizontal Scaling) to hundreds of nodes.
This is mainly to address the scaling issues that arise with an increase in the volume of data being analyzed and an increase in load, when the data can no longer be stored and processed on the same physical server
ClickHouse provides sharding and replication “out of the box”, they can be flexibly configured separately for each table. Apache ZooKeeper is required for replication (version 3.4.5+ is recommended). ZooKeeper is not a strict requirement in some simple cases, you can duplicate the data by writing it into all the replicas from your application code. This approach is not recommended, in this case ClickHouse won’t be able to guarantee data consistency on all replicas. This remains the responsibility of your application.
Replication works at the level of an individual table, not the entire server. A server can store both replicated and non-replicated tables at the same time.
Sharding
Sharding(horizontal partitioning) in ClickHouse allows you to record and store chunks of data in a cluster distributed and process (read) data in parallel on all nodes of the cluster, increasing throughput and decreasing latency. For example, in queries with GROUP BY ClickHouse will perform aggregation on remote nodes and pass intermediate states of aggregate functions to the initiating node of the request, where they will be aggregated.
For sharding, a special Distributed engine is used, which does not store data, but delegates SELECT queries to shard tables (tables containing pieces of data) with subsequent processing of the received data.
Writing data to shards can be performed in two modes: 1) through a Distributed table and an optional sharding key, or 2) directly into shard tables, from which data will then be read through a Distributed table. Let’s consider these modes in more detail.
In the first mode, data is written to the Distributed table using the shard key. In the simplest case, the sharding key may be a random number, i.e., the result of calling the rand () function. However, it is recommended to take the hash function value from the field in the table as a sharding key, which will allow, on the one hand, to localize small data sets on one shard, and on the other, will ensure a fairly even distribution of such sets on different shards in the cluster. For example, a user’s session identifier (sess_id) will allow localizing page displays to one user on one shard, while sessions of different users will be distributed evenly across all shards in the cluster (provided that the sess_id field values have a good distribution). The sharding key can also be non-numeric or composite. In this case, you can use the built-in hashing function cityHash64 . In the this mode, the data written to one of the cluster nodes will be automatically redirected to the necessary shards using the sharding key, however, increasing the traffic.
A more complicated way is to calculate the necessary shard outside ClickHouse and write directly to the shard table. The difficulty here is due to the fact that you need to know the set of available nodes-shards. However, in this case, the inserting data becomes more efficient, and the sharding mechanism (determining the desired shard) can be more flexible.However this method is not recommended.
Replication
ClickHouse supports data replication , ensuring data integrity on replicas. For data replication, special engines of the MergeTree-family are used:
- ReplicatedMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedAggregatingMergeTree
- ReplicatedSummingMergeTree
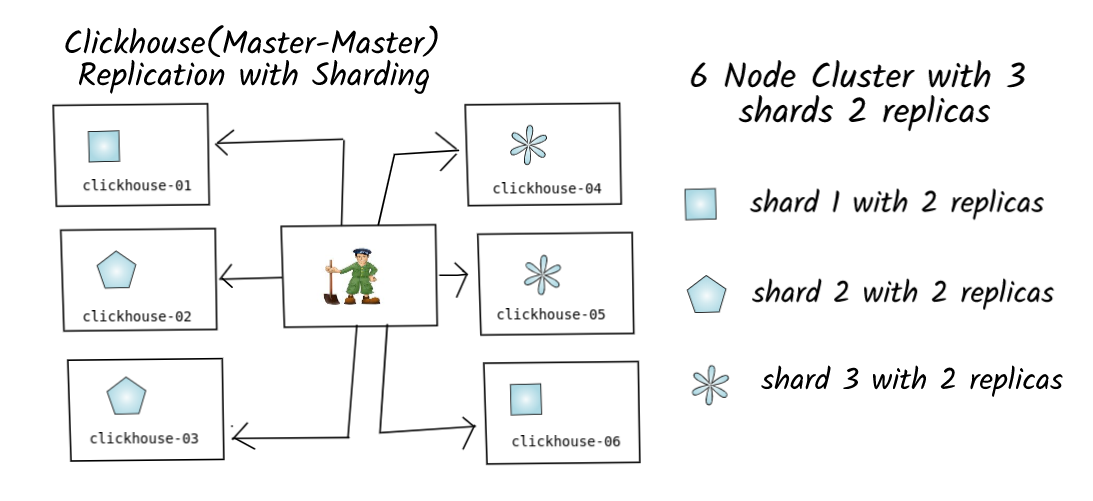
Replication is often used in conjunction with sharding — Master/Master replication with Sharding was the common strategy used in OLAP(Column Oriented ) Databases which is also the case for Clickhouse.
For example, we use a cluster of 6 nodes 3 shards with 2 replicas. It should be noted that replication does not depend on sharding mechanisms and works at the level of individual tables and also since the replication factor is 2(each shard present in 2 nodes)
Sharding distributes different data(dis-joint data) across multiple servers ,so each server acts as a single source of a subset of data.Replication copies data across multiple servers,so each bit of data can be found in multiple nodes.
- Scalability is defined by data being sharded or segmented
- Reliability is defined by data replication
Data sharding and replication are completely independent. Sharding is a natural part of ClickHouse while replication heavily relies on Zookeeper that is used to notify replicas about state changes.
Distributed Table Schema
The only remaining thing is distributed table. In order ClickHouse to pick proper default databases for local shard tables, the distributed table needs to be created with an empty database(or specifying default database). That triggers the use of default one.
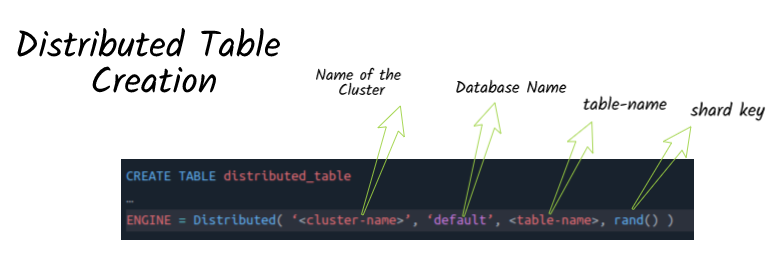
When query to the distributed table comes, ClickHouse automatically adds corresponding default database for every local shard table.
The distributed table is just a query engine, it does not store any data itself. When the query is fired it will be sent to all cluster fragments, and then processed and aggregated to return the result. Distributed table can be created in all instances or can be created only in a instance where the clients will be directly querying the data or based upon the business requirement. It is recommended to set in multiples.
In this post we discussed in detail about the basic background of clickhouse sharding and replication process, in the next post let us discuss in detail about implementing and running queries against the cluster.
4
1 Comment